From AI Office

In the race to automate medical coding, healthcare leaders are discovering a hard truth:
Large Language Models are incredible readers — but unreliable logicians.
You can feed a standard LLM a clinical chart and it will extract diagnoses instantly. But it often fails to understand the rules of existence. It sees the word “Diabetes” and bills for it — even if the word appears in a Family History section.
This is a hallucination of context.
In healthcare, that isn’t a glitch. It’s a liability.
At Encipher Health, the way we think about clinical documentation is fundamentally structural. A patient chart is not viewed as a narrative to summarize, we treat it as a mathematical object to solve.
Through the lens of Ontology Logs (Ologs), each element within the chart is treated as part of a defined mathematical structure. This way of thinking emphasizes constraint, clarity, and traceability in every step of reasoning.
The limitations of today’s LLM-driven coding systems aren’t random. They stem from architecture.
Current LLM systems struggle in three critical ways:
Hallucination - generating conclusions not logically supported by the source text. The model predicts what is statistically likely, not what is structurally valid.
Confabulation - producing explanations that sound coherent but are not grounded in deterministic reasoning. The answer appears justified, but the reasoning cannot be reproduced step by step.
Non-informativeness - defaulting to vague or unspecified codes when specificity is required, instead of flagging missing information. The system fills gaps instead of enforcing completeness.
These are not surface-level bugs.
They are structural consequences of probabilistic prediction.
An LLM predicts the next most likely token. Medical coding enforces rules of existence. Probability and proof are not the same thing.
A patient chart looks like a narrative.
But underneath the paragraphs and bullet points, it is something far more rigid.
It has containers, it has rules, it has boundaries, it has allowed and disallowed intersections.
Instead of viewing documentation as text to summarize, it can be understood as a structured system governed by constraints.
Through the lens of Ontology Logs (Ologs), every element inside a chart becomes part of a defined mathematical relationship:
In this framing, documentation behaves less like literature and more like architecture.
When documentation is treated as structured space rather than flowing language, hallucinations become structural violations. Confabulation becomes impossible because every conclusion must follow a defined path. And vague coding becomes visible as incomplete construction, not hidden behind confident language.
That shift — from reading to reasoning — is where the olog begins.
When a standard LLM reads a chart, it sees a stream of tokens and relies on probability to predict meaning.
When our system reads a chart, it sees a structured topological space built from strict containers and logical connections.
We define the chart using algebraic data types:
By forcing text into mathematical containers, we remove the ambiguity that causes hallucinations. A diagnosis cannot exist unless it satisfies formal constraints.
The most common AI coding error is billing conditions that are not active:
Standard LLMs are keyword-driven. They see a disease term and react.
We stop this with a mathematical structure called a Pullback — a universal filter that enforces existence rules.
A valid diagnosis must satisfy:
Valid Diagnosis = Mention × (Section where isValid = True)
If the section is not valid for billing, the equation fails.
Input:
“Family History: Mother had diabetes.”
Standard LLM:
Detects “Diabetes” → bills E11.9
Encipher Olog:
Result: The equation collapses to null.
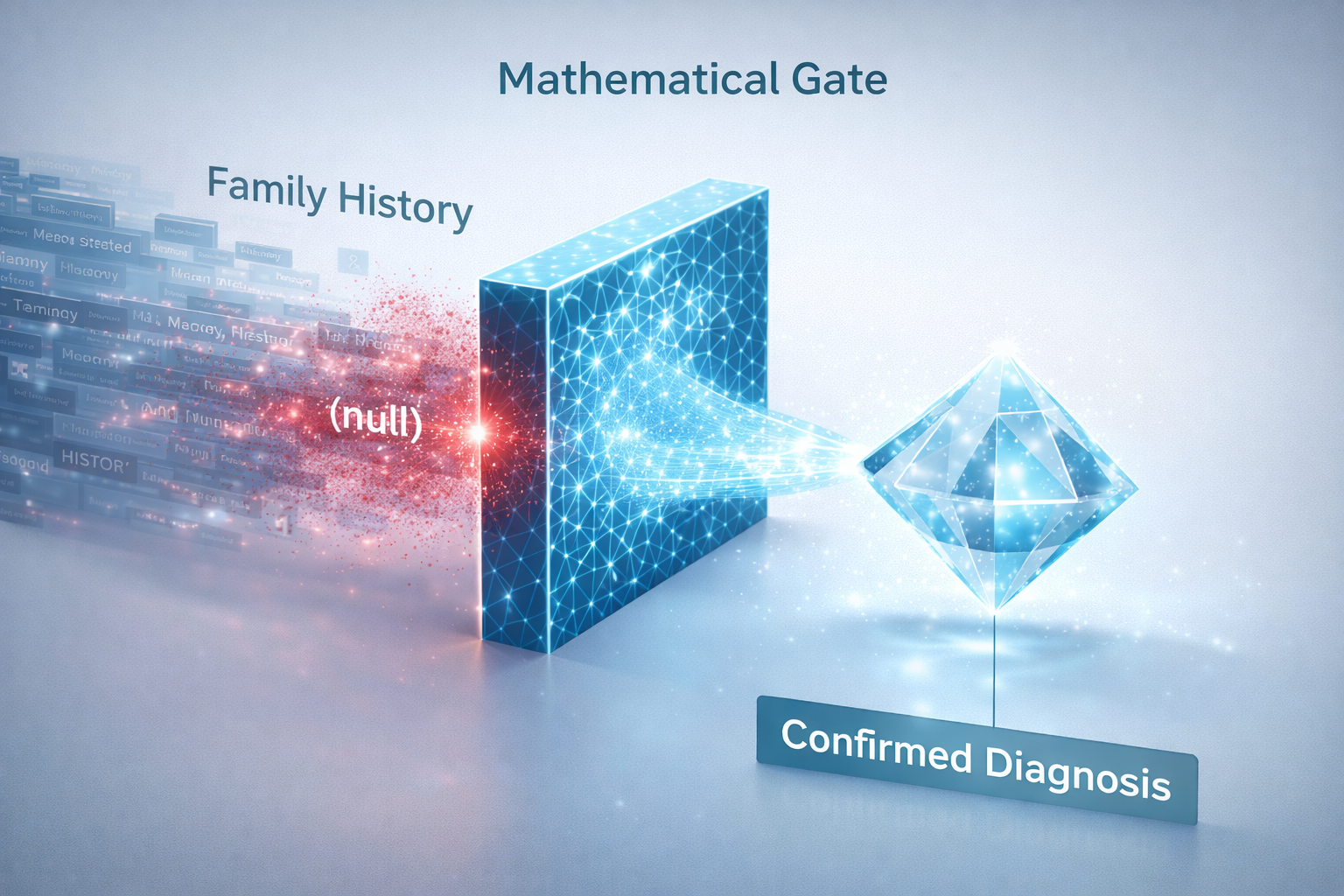
The system doesn’t suppress the diagnosis. It proves it cannot exist.
The biggest weakness of standard LLMs is opacity. Ask why a code was assigned, and the model generates a plausible explanation you cannot verify.
Encipher replaces the black box with a glass box.
Every code includes a deterministic audit trace.

Standard LLM Audit | Encipher Mathematical Audit |
|---|---|
Target Code: S72.92XA This sounds confident but is not auditable. | Target Code: S72.92XA
|
This is not a guess. It is a derivation.
Replacing reading with reasoning unlocks three critical advantages:
Diagnoses from invalid sections cannot become billable because the architecture forbids it.
Specificity is enforced. Missing modifiers trigger clarification instead of vague coding.
Every decision includes a transparent logical lineage.
Healthcare does not need confident predictions.
It needs systems that can prove their decisions."
You cannot audit a probability. You can audit a proof.
Encipher Health is moving healthcare AI from the era of guessing to the era of engineering. We don’t just assign codes — we mathematically prove why they are correct.
And once you see coding through a glass box, black-box AI becomes very hard to trust again.
Schedule a demowith Encipher Health and watch your charts move through a system built for verification.
Most AI coding platforms rely on Large Language Models that predict diagnoses based on statistical likelihood. Encipher treats clinical documentation as a structured mathematical system. Instead of asking “What diagnosis is most likely?” we ask, “Does this diagnosis satisfy formal structural constraints?” Every billable code must pass deterministic validation rules. If it fails, it does not exist in the system. This eliminates contextual hallucinations.
LLMs are built to predict the most statistically probable next token. They optimize for fluency and plausibility — not rule enforcement. Medical coding, however, is governed by strict structural and contextual requirements. A diagnosis must meet defined billing conditions to exist as valid. Clinical language adds complexity: many terms are derived from Latin and Greek roots, include rare modifiers, or appear infrequently in training data. When context is ambiguous or tokens are statistically sparse, the model interpolates based on probability rather than validation. The result can be linguistically correct but structurally invalid conclusions. When probability replaces constraint enforcement, hallucination becomes an architectural outcome — not a random glitch.
Auditors do not accept “the model predicted it.” They require traceability. Encipher provides a full logical lineage from raw text to final code. Because each decision is derived from explicit structural constraints, it can be independently verified. This transforms coding from probabilistic output into reproducible reasoning.
Traditional AI systems often default to vague or unspecified codes. Encipher detects structural incompleteness. If required modifiers or specificity conditions are missing, the system flags the gap rather than guessing. This protects both compliance and revenue integrity.
Yes. Because the system is constraint-based, new specialties or rule sets can be encoded as additional structural validations. Instead of retraining a probabilistic model, the architecture expands through formal definitions. Scalability becomes an engineering problem, not a statistical gamble.
Healthcare risk adjustment, compliance oversight, and payer scrutiny are increasing. Confidence is no longer sufficient. Organizations need systems that can defend every assigned code with traceable logic. You cannot audit a probability. You can audit a proof.
AI Powered Medical Coding Intelligence





© 2026 Encipher Health Inc. All rights reserved.
1007 N Orange St. 4th Floor
Ste. 1382 Wilmington, New Castle,
DE- 19801
+1 (302) 353-1211
Don't Miss Out on Important News and Insights.

